
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 노션
- serverless
- S3
- 2020년
- 하이트진로
- 알고리즘
- AWS
- HEXO
- React
- github pages
- amqp
- zookeeper
- Kafka
- 회고
- 머신러닝
- 백준
- 아키텍처
- 맥주
- billing
- ddd
- API Gateway
- Zappa
- 메세지큐
- CloudWatch
- finops
- AWSKRUG
- LAMBDA
- Leetcode
- 도메인 주도 설계
- Notion
- Today
- Total
인생은 고통의 연속
Machine Learning - 손실 줄이기(이전 포스트) 본문
반응형
2018-08-29 작성
본 게시물은 구글 머신러닝 단기집중과정 스터디을 참고하여 작성되었습니다.
손실 줄이기(Reducing Loss)
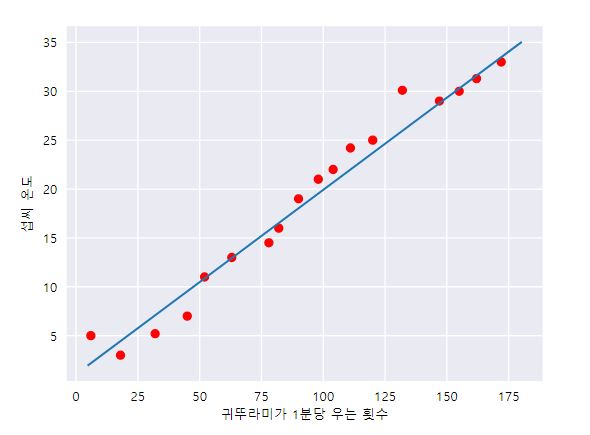
앞에서 배운 모델의 방정식이 있다.
 모델의 방정식
모델의 방정식
하지만 단순히 직선으로 이뤄져있기 때문에 위의 방정식으로는 각 데이터마다 차이가 크다.
예를 들어, 귀뚜라미가 150번 울때의 온도는 방정식과 거의 동일하지만 130번 울때의 온도는 약 5도로 차이가 크다.
따라서 머신러닝은, 모델의 방정식을 최대한 입력된 데이터(학습데이터)와 가깝게(손실율이 적게) 만드는 것이 목표이다.
반복학습(Iterative learning)
- 핫 앤 콜드(Hot & Cold)
- 술래가 눈을 감은 상태에서 임의로 정한 물건과 술래가 가까우면 핫(Hot), 멀어지면 콜드(Cold)를 외치는 게임
- 머신러닝도 동일하게 w₁의 값을 계속 바꿔가며(Hot & Cold) 가장 손실율이 적은 모델(임의로 정한 물건)을 찾는 것이다.
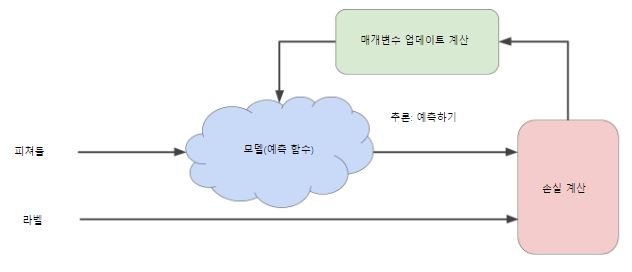 Figure 1 : 반복 방식의 모델 학습
Figure 1 : 반복 방식의 모델 학습
머신러닝 알고리즘
머신러닝 알고리즘으로 모델을 학습하는데 사용하는 반복적인 시행착오 과정
하나 이상의 특성을 입력하여 하나의 예측을 출력함
모델(예측 함수)
하나의 특성으로 하나의 예측을 반환하는 모델1 y' = b + w₁x₁ - x₁ = 10, b = 0, w₁ = 0 이면 y’ = 0 + 0(10) = 0
- x₁이 10일때 올바른 라벨(출력값=y)이 10이라면? -> 손실 발생!
- 그럼 손실 계산은 어떻게 할까?
손실 계산(Compute Loss)
- Figure 1에서 손실 계산에서 사용되는게 손실 함수
- 손실 함수는 두개의 입력 값을 가짐
- y’: 특성 x에 대한 모델의 예측값(학습을 통해서 만든 모델의 결과 값)
- y : 특성 x에 대한 올바른 라벨(실제 데이터 값)
매개변수 업데이트 계산(compute parameter updates)
- 모델, 손실 계산을 통해서 매개변수인 b와 w₁의 값을 변경
다시 처음부터 반복
- 가장 손실 값이 낮은 모델의 매개변수를 찾을때까지 반복함
- 전체 손실이 변하지 않거나 매우 느리게 변한다면? 모델이 수렴(converged)했다고 한다
매개변수 업데이트 계산?
손실 계산은 y, y’ 두개의 입력값으로 손실 함수를 만들어서 계산한다고 하는데
매개변수 업데이트 계산은 뭘로 한다는 걸까?
w₁와 b 값을 업데이트 한다는건데 뭘까?
- 대충 이런 것이다.(일단 w₁만으로 설명)
- w₁값을 업데이트한다.(매개변수 업데이트)
- w₁을 업데이트할때마다 손실 계산을 함
- 그럼 아래와 같은 형식의 그래프가 나옴
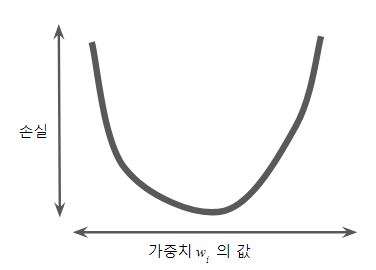 Figure 2 : 볼록 함수 모양의 그래프
Figure 2 : 볼록 함수 모양의 그래프 - 그렇다면 최소값인 지점은? 기울기가 정확하게 0인 지점(손실 함수가 수렴하는 지점)
- 문제는 모든 w₁ 값의 손실 계산을 하는건 비효율적인 방법
- 만약 w₁가 실수 전체 범위라면 0~1 사이에 값만 넣어도 무한대의 시도가 필요함
경사하강법(Gradient Descent)
- 모든 w₁ 값을 계산하는 것은 비효율적이므로 임의의 값을 시작으로 일정 간격으로 손실 그래프의 기울기를 계산!(=편미분)
- 미분(Derivatives)
- 해당하는 점의 기울기를 구한 값
- ex) x=2일때 기울기
- 편미분(Partial derivatives)
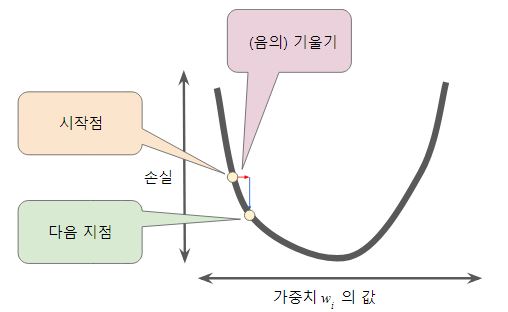 Figure 3 : 편미분
Figure 3 : 편미분- 특정 구간의 기울기를 구한 값
- ex) x=2~4 구간의 기울기
- 미분(Derivatives)
- 모든 값을 계산할 필요없이 적절한 간격을 설정하여 구하면 됨
- 여기서 말하는 간격이 학습률을 뜻함!
- 경사하강법에서는 음의 기울기를 사용(↘방향)
- 즉, 가중치가 증가할때 손실은 줄어들어야함
- 따라서 기울기도 벡터(방향과 크기를 가짐)
- 다음 지점을 결정하는법 = 기울기 X 학습률 or 보폭(스칼라)
학습률(Learning Rate)
- 초매개변수(Hyperparameters) : 프로그래머가 머신러닝 알고리즘에서 조정하는 값
- 학습률이 너무 작으면 학습 시간이 오래 걸림
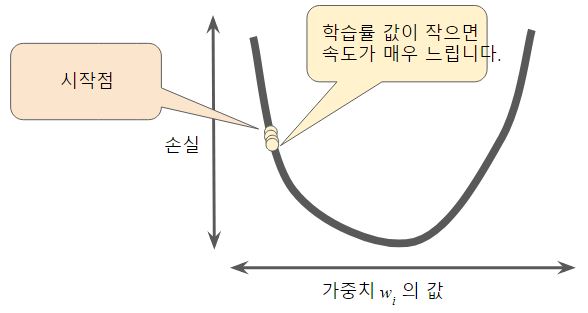 Figure 4 : 학습률이 너무 작아 오래 걸림
Figure 4 : 학습률이 너무 작아 오래 걸림 - 반대로 너무 크면 곡선의 최저점을 이탈함
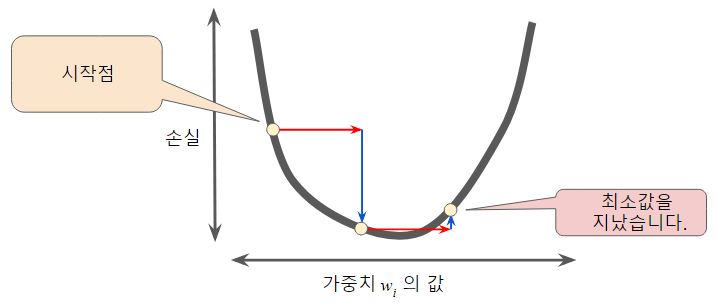 Figure 5 : 학습률이 너무 커 최저점을 이탈
Figure 5 : 학습률이 너무 커 최저점을 이탈 - 골디락스 학습률
- 효율적으로 결과를 얻을 수 있는 학습률
- 실버 불릿같은 존재(알면 한번에 그렇게 했겠지…)
확률적 경사하강법(Stochastic Gradient Descent)
- 데이터 세트가 엄청나게 많거나 특성이 많은 경우, 전체 데이터를 경사하강법을 통해서 학습하면 오래걸림
- 따라서 무작위로 일부 데이터를 뽑아서 학습시킴
- 데이터는 적어지기 때문에 노이즈(오차)가 발생할 수 있음
반응형
'개발스터디&모임 > 구글 머신러닝 단기집중과정 스터디' 카테고리의 다른 글
| Machine Learning - ML로 전환하기(이전 포스트) (0) | 2018.11.21 |
|---|---|
| Machine Learning - ML 문제로 표현하기(용어 정리)(이전 포스트) (0) | 2018.11.21 |
| Machine Learning - 첫걸음(이전 포스트) (0) | 2018.11.21 |
Comments